- 卓越的多语言文本渲染:支持英语、中文、韩语、日语等多种语言的高精度文本生成,保持字体细节和布局一致性
- 多样化艺术风格:从照片级真实到印象派绘画,从动漫美学到极简设计,流畅适应各种创意提示
Qwen-Image 原生工作流示例
在本篇文档所附工作流中使用的不同模型有三种- Qwen-Image 原版模型 fp8_e4m3fn
- 8步加速版: Qwen-Image 原版模型 fp8_e4m3fn 使用 lightx2v 8步 LoRA,
- 蒸馏版:Qwen-Image 蒸馏版模型 fp8_e4m3fn
| 使用模型 | VRAM Usage | 首次生成 | 第二次生成 |
|---|---|---|---|
| fp8_e4m3fn | 86% | ≈ 94s | ≈ 71s |
| fp8_e4m3fn 使用 lightx2v 8步 LoRA | 86% | ≈ 55s | ≈ 34s |
| 蒸馏版 fp8_e4m3fn | 86% | ≈ 69s | ≈ 36s |
1. 工作流文件
更新 ComfyUI 后你可以从模板中找到工作流文件,或者将下面的工作流拖入 ComfyUI 中加载
下载官方版 JSON 格式工作流
蒸馏版下载蒸馏版JSON 格式工作流
2. 模型下载
你可以在 ComfyOrg 仓库找到的版本- Qwen-Image_bf16 (40.9 GB)
- Qwen-Image_fp8 (20.4 GB)
- 蒸馏版本 (非官方,仅需 15 步)
- 蒸馏版本原始作者建议在 15 步 cfg 1.0
- 经测试该蒸馏版本在 10 步 cfg 1.0 下表现良好,根据你想要的图像类型选择 euler 或 res_multistep
3. 按步骤完成工作流
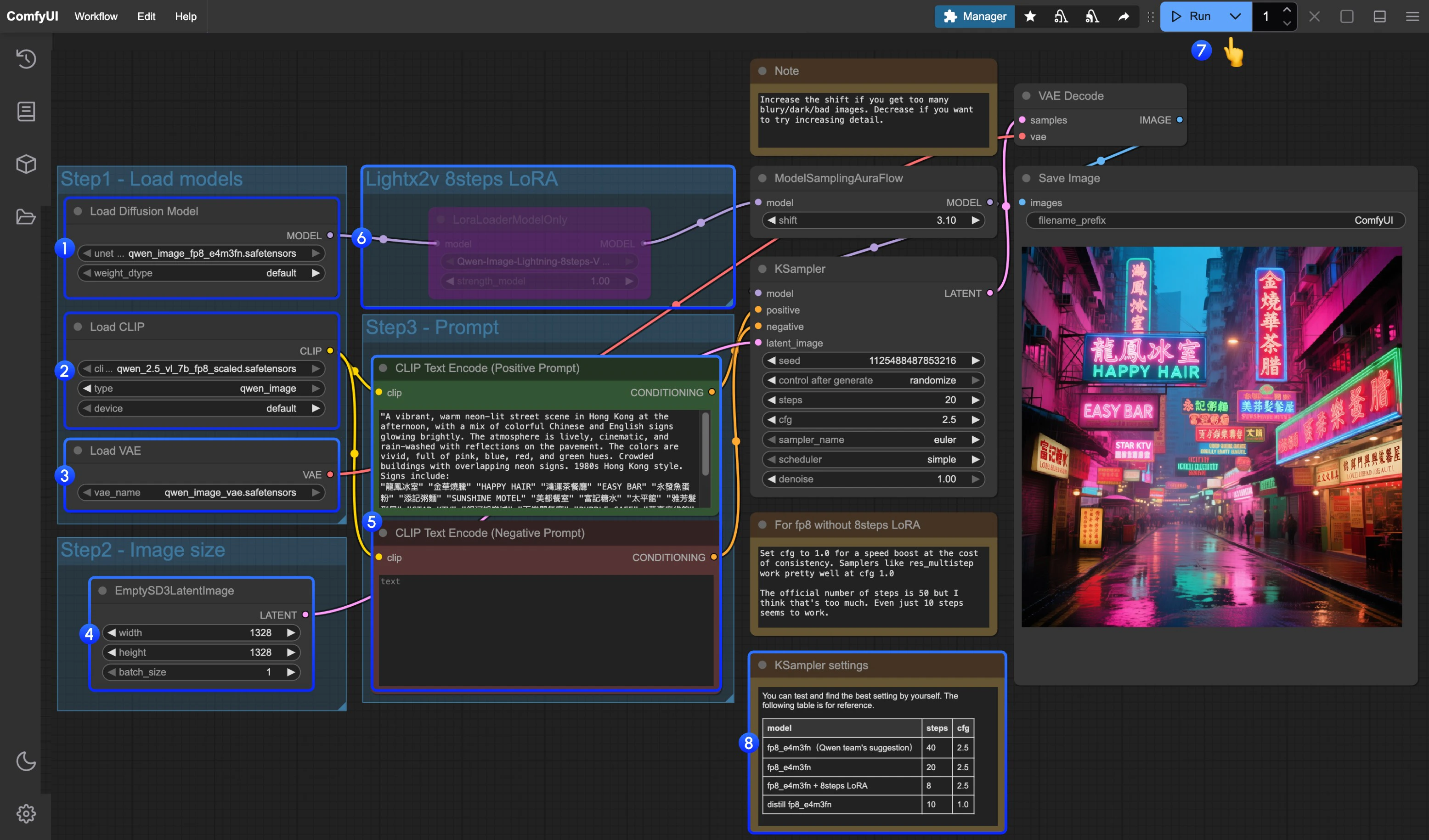
- 确保
Load Diffusion Model节点加载了qwen_image_fp8_e4m3fn.safetensors - 确保
Load CLIP节点中加载了qwen_2.5_vl_7b_fp8_scaled.safetensors - 确保
Load VAE节点中加载了qwen_image_vae.safetensors - 确保
EmptySD3LatentImage节点中设置好了图片的尺寸 - 在
CLIP Text Encoder节点中设置好提示词,目前经过测试目前至少支持:英语、中文、韩语、日语、意大利语等 - 如果需要启用 lightx2v 的 8 步加速 LoRA ,请选中后用
Ctrl + B启用该节点,并按 序号8处的设置参数修改 Ksampler 的设置设置 - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流 - 对于不同版本的模型和工作流的对应 KSampler 的参数设置
蒸馏版模型和 lightx2v 的 8 步加速 LoRA 似乎不能同时使用,你可以测试具体的组合参数来验证组合使用的方式是否可行